整理常见实现防盗链功能的方案
当前位置:点晴教程→知识管理交流
→『 技术文档交流 』
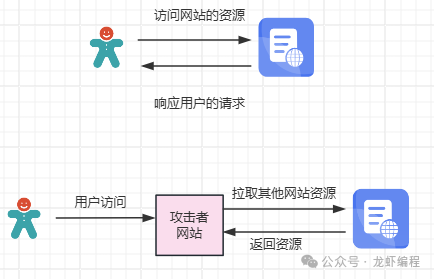
在热门平台上有许多的热点新闻,热门的图片、视频等资源,每天都吸引大量的用户观看和下载。于是就有攻击者通过爬虫等一系列技术手段,把热门平台上的资源拉取到自己的网站然后呈现给用户,从而攻击者达到了即不用提供资源也能赚钱的目的,如下图所示盗取资源的过程图:
为此,热门平台为了防止其他的小站点盗取其资源,于是就使用防盗链来保护自身资源不被窃取。下面我们聊聊常见的几种防盗链实现方案。 1、Nginx实现方案 在HTTP协议头里有一个Referer的字段,Referer可以告诉服务器该网页请求是从哪里链接过来的,如下的请求头截图:
那么可以利用请求头上的Referer携带的值,使用Nginx在网关层做防盗链,这个也是最简单的实现防盗链功能的方式之一。 Nginx通过拦截访问资源的请求,通过valid_referers关键字定义的白名单,校验请求头中Referer地址是否为本站,如不是本站请求,那么就拒绝这个请求的访问,Nginx的配置如下所示:
Nginx的方式可以限制大多数普通的非法请求,但不能限制有针对性的攻击请求,因为攻击者可以通过伪造Referer信息来绕过Nginx的检查。 2、SpringBoot的过滤器实现方案 过滤器同样是使用Referer的原理,在SpringBoot中声明一个过滤器,然后获取到当前请求头当中的Referer,如下代码所示:
过滤器中通过比对Referer中的来源,如果它不是我们允许的来源,那么就直接拒绝请求。其实攻击者依然可以伪装Referer,所以还是无法彻底解决资源被盗取的问题。 3、token验证的实现方案
用户登录之后服务器通过生成一个token,然后每次用户请求后端都需要将token携带给服务器,如果请求中没有token或者token解析失败,就直接拒绝请求的访问。 但是这种方式攻击者依然可以通过先请求我们的登录接口拿到token后,然后把token放在请求头上,继而达到伪装成正常的用户请求,这样就绕过token验证。 4、时间戳验证方案 正常的用户打开一个网页之后总会停留一定的时间,即使此用户停留的再短也会比其他的窃取工具(如爬虫)停留的时间长,利用这个特点在每次响应客户端的时候,后端给客户端响应一个时间戳,然后前端携带这个时间戳请求后端接口,后端拿到时间戳后与当前的时间做比对,核心的代码如下所示:
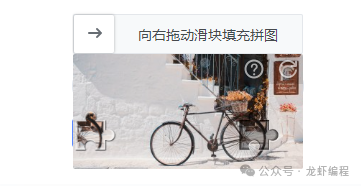
请求种的时间戳与当前的时间计算差值,如果差值大于设定的值,我们就认为是正常用户的请求,反之认定为盗窃用户请求,则拒绝访问。时间戳的方式也存在一定的误判,用户可能确实就在网页上停留很短的时间。 5、图形验证码的实现方案 图形验证码是一种比较常规的限制办法,在下载资源,浏览关键信息的时候,都必须要求用户手动操作验证码,典型的图形验证码如下所示:
使用图形验证码使得一般的爬虫工具无法绕过校验,从而起到保护资源的目的。 防盗链其实不是百分之百可以防住资源被盗窃的问题,它只能增加破解的难度,因为只要网站的数据能够正常访问,那攻击者就能伪装成正常用户来窃取数据。在一些大公司中,他们会去结合大数据分析用户的行为,将一些不正常的用户行为定义到黑名单中,然后在黑名单上的用户请求会被拦截。 该文章在 2025/1/9 10:06:21 编辑过 |
关键字查询
相关文章
正在查询... 



|


 400 186 1886
400 186 1886