python自动化系列:自动提取PDF表格数据并保存为Excel文件
|
admin 2025年8月28日 1:49
本文热度 892
2025年8月28日 1:49
本文热度 892
|
作品名称:自动提取PDF表格数据并保存为Excel文件开发环境:PyCharm 2023.3.4 + python3.7用到的库:pdfplumber、pandas、logging(用于日志记录的一个强大工具)作品简介:该实例使用pdfplumber库来提取PDF文件中的表格数据,并使用pandas库将这些数据保存为Excel文件。此外,代码还使用了logging库来记录操作过程中的信息和错误。
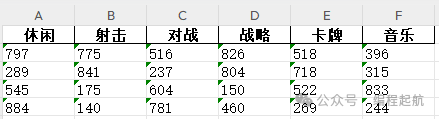
以下是代码的详细说明:
"""提取pdf的表格数据保存为Excel文件"""import pdfplumberimport pandas as pdimport logging
logging.basicConfig(level=logging.INFO)
# PDF文件路径pdf_path = 'leisure.pdf'
# 使用pdfplumber打开PDF文件try: with pdfplumber.open(pdf_path) as pdf: all_dfs = []
for page in pdf.pages: tables = page.extract_tables()
for table in tables: df = pd.DataFrame(table[1:], columns=table[0]) all_dfs.append(df)
combined_df = pd.concat(all_dfs, ignore_index=True)
excel_path = "table_from_page.xlsx" combined_df.to_excel(excel_path, index=False)
logging.info(f"表格数据已保存为Excel文件:{excel_path}")
except Exception as e: logging.error(f"处理PDF或保存Excel时发生错误:{str(e)}")
阅读原文:原文链接
该文章在 2025/8/28 15:45:50 编辑过






 400 186 1886
400 186 1886

